
Автор статьи рассказывает о методологии проектирования процессов управления ИТ-активами, предлагая систематический подход к внедрению решений через последовательное формулирование целей ("Зачем?"), определение содержания ("Что?"), распределение ответственности ("Кто?") и выбор технических средств ("Как?"). Особое внимание уделяется практическому опыту реализации проекта для государственной ИТ-организации, где рассматривается комплекс аспектов: от инвентаризации и управления жизненным циклом активов до обеспечения эффективного взаимодействия между бизнес-процессами заказчика и возможностями ИТ-инфраструктуры. Подчеркивается важность гибкости и адаптивности системы, чтобы она соответствовала изменяющимся потребностям пользователей и организации в целом.
Процесс управления инцидентами и запросами пользователей – наиболее зрелая практика управления во многих современных ИТ-организациях1. Для многих руководителей он является одним из основных источников численной информации и о качестве поддержки пользователей (о деятельности), и о качестве предоставляемых услуг (об услугах), и о загрузке персонала (о ресурсах). В данной статье рассматривается структурированный набор нормированных показателей, предназначенных для измерения и оценки процесса, и рассматриваются некоторые аспекты применения этих показателей на практике.
Краткая справка по процессу
Назначение процесса – обеспечение качества ИТ-услуг за счет скорейшего устранения инцидентов и своевременного выполнения запросов на обслуживание.
Основная особенность процесса управления инцидентами и запросами пользователей, которая напрямую и довольно существенно влияет на его измерение – так называемая функциональная эскалация. Вообще функциональная эскалация – это передача некоторой задачи от одной функциональной группы в другую, обладающую более высокой компетенцией, техническими или иными возможностями для решения данной задачи. В рамках рассматриваемого процесса такими задачами, естественно, являются инциденты и запросы пользователей. Это значит, что один инцидент или запрос может последовательно обрабатываться несколькими группами, и итоговый успех (или неуспех) складывается из действий (или бездействия) многих специалистов (Рисунок 1).
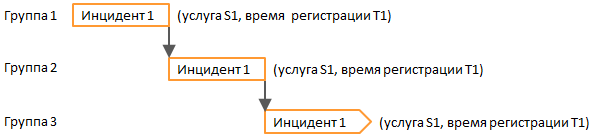
Рисунок 1. Передача инцидента / запроса между группами в рамках функциональной эскалации
Ключевые практики процесса2, первоочередные для измерения:
- оперативная реакция групп поддержки на поступающие инциденты и запросы;
- минимизация переназначений инцидентов и запросов;
- повторное использование знаний для сокращения времени диагностики и решения;
- обработка инцидентов и запросов с первого раза, без потерь времени на доработки.
Измерение результативности процесса
Как следует из назначения процесса, его результативность определяется тремя факторами:
- своевременностью обработки запросов пользователей;
- скоростью устранения инцидентов;
- удовлетворенностью пользователей качеством ИТ-поддержки.
Давайте последовательно разберемся с измерением этих факторов.
Своевременность обработки запросов пользователей
На первый взгляд, своевременность обработки запросов измерить несложно3:
| (1) |
где R – количество своевременно обработанных запросов, а N – общее количество запросов, обработанных за некоторый период времени.
Однако за простотой этой формулы скрывается несколько любопытных особенностей.
Во-первых, если применять такую формулу «в лоб», то она не стимулирует сотрудников обрабатывать запросы, которые уже просрочены. В самом деле, если метрика рассчитывается по фактически исполненным запросам (знаменатель N), то если я откладываю обработку просроченного запроса, я дважды выигрываю:
- исключая данный запрос из расчета метрики;
- и высвобождая время для обработки еще не просроченных запросов.
Само собой, рано или поздно хватятся, и просроченный запрос придется обработать. Но кому интересно, особенно в конце отчетного периода, за который вот-вот выплатят премию, что будет когда-то потом?
Для решения данной проблемы определение K1,1 можно модифицировать, точнее – уточнить определение операнда N. А именно, пусть N помимо фактически решенных запросов, будет включать в себя запросы, срок обработки которых на момент окончания отчетного периода истек, а они так и не были решены. Тогда «зависшие» запросы будут снижать значение метрики, и шансы, что на них обратят внимание, возрастут.
Во-вторых, определение K1,1 не учитывает, насколько был нарушен срок обработки запроса. Обычно пользователю не все равно, был ли его запрос просрочен на 5 минут или на неделю (мы, разумеется, имеем в виду рабочее время, а не новогодние праздники).
Для того чтобы учесть, насколько нарушен срок, определим показатель своевременности обработки следующим образом:
| (2) |
где Ri рейтинг обработки i-того запроса, равный 1, если i-тый запрос обработан в срок и 0 в случае, если он просрочен. А вес Wi определяется формулой
| (3) |
В (3) ti – фактическое время обработки запроса (рассчитанное по календарю рабочего времени или, если возможно, по календарю, указанному в SLA, согласно которому обрабатываются данные запросы), Ti – максимальное время обработки4, n – натуральное число, которое является параметром алгоритма (обычно его принимают равным 1). Тогда чем сильнее просрочен i-тый запрос, тем больше его вес Wi, снижающий значение метрики (поскольку ti > Ti). Причем, чем больше значение параметра n, тем быстрее возрастает Wi с увеличением срока обработки (заметим, что при n=0 определение K1,2 становится тождественным K1,1 – длительность обработки просроченных запросов перестает оказывать влияние на значение метрики).
Для наглядной демонстрации приведем значения метрики K1,2 на некотором примере. Предположим за некоторый период мы обработали 20 запросов. Из них 19 в срок (равный четырем рабочим часам), а один – просрочили. Рисунок 2 показывает, какое влияние на значение метрики K1,2 оказывает фактическое время решения просроченного запроса:
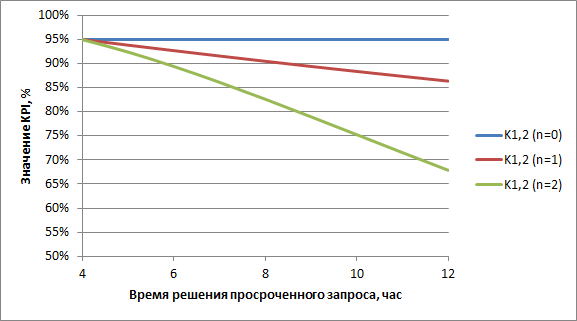
Рисунок 2. Влияние длительности просрочки на значение K1,2
Таким образом, введение веса Wi, зависящего от длительности просрочки, стимулирует торопиться даже с обработкой уже просроченных запросов.
Однако такая модификация метрики имеет и обратную сторону – сложность расчета. Дело в том, что расчет K1,2 несложно выполняется только по запросам, фактически решенным за период (поскольку у них известно фактическое время решения). Если же мы захотим добавить к этому расчету запросы, которые должны были быть решены на момент окончания периода, но так и не были решены, нам придется дополнительно рассчитывать фактическую длительность обработки таких запросов на момент окончания отчетного периода, причем рассчитывать корректно – по соответствующему календарю. А это серьезное усложнение расчета. Если же мы будем игнорировать необработанные, но уже просроченные запросы (как в оригинальном определении K1,1), то стимулирующий эффект K1,2 хоть и остается (откладывать надолго невыгодно, поскольку таким образом мы увеличиваем просрочку и снижаем значение метрики в будущих периодах), но существенно ослабляется, поскольку ужасающие последствия в неопределенном будущем могут мотивировать меньше, чем неприятности сегодня или завтра.
Третья особенность формулы K1,1 заключается в том, что она корректно применяется к процессу в целом, но ее применение для оценки работы какой-либо конкретной группы затруднено. Причина этого затруднения – упомянутая ранее функциональная эскалация. В самом деле, применение K1,1 (или K1,2) к конкретной группе требует выполнять расчет в разрезе групп, то есть рассчитывать значение метрики по запросам, обработанным той или иной группой. Но что делать, если запрос обрабатывался несколькими группами? Довольно часто запрос попадает в расчет той группы, которая обрабатывала его последней. Но вряд ли это можно назвать справедливым решением, ведь эта группа могла получить запрос за пару минут до окончания срока решения или еще хуже – уже просроченным. Что же можно сделать?
По большому счету нам известно два способа – системный, но не очень реалистичный и быстрый, но немного «шарлатанский» (недостаточно обоснованный). Выбирайте, какой больше подходит вам – оба неидеальны.
Системный способ заключается в стандартизации и нормировании операций, необходимых для обработки запросов (теоретически такое нормирование возможно и для решения инцидентов). Типовые запросы должны быть представлены в виде стандартных цепочек заданий с известным составом, последовательностью и сроками исполнения. После этого передача запроса заменяется назначением заданий в составе запроса, и качество работы группы оценивается аналогично K1,2, но уже по назначенным в группу заданиям. Немного забегая вперед, заметим, что инциденты с длинными цепочками эскалаций «укорачиваются» за счет введения каталога инфраструктурных услуг и OLA так, чтобы у каждой группы был определен свой состав услуг и свои сроки обработки поступающих к ним инцидентов (Рисунок 3). Нормируется также и время пребывания инцидентов на каждой из линий поддержки.

Рисунок 3. Привлечение других групп к решению инцидента / запроса на основании OLA
Когда все работы нормированы и регламентированы, измерение своевременности выполняется несложно. Но эта дорога вряд ли может быть легко пройдена большинством известных нам организаций. И потому, что слишком часто меняются современные информационные технологии, чтобы такая нормировка сохраняла свою справедливость в долгосрочной перспективе. И потому, что введение OLA имеет побочные эффекты, не всегда желательные и посильные для ИТ-руководителей5. А применение данного способа без должной подготовки может привести к такой оценке работы отдельных групп, которая игнорирует общую результативность процесса (вывод может быть таким: «все группы работают хорошо, несмотря на то, что существенная доля запросов просрочена»). Поэтому этот путь не универсален и уж точно не дает быстрых результатов.
А быстрый способ – признать, что четко выделить ответственность каждой группы в обработке запроса (или инцидента) нельзя. Таково свойство процесса. Свой вклад в скорость решения инцидента вносят все участники его обработки. Тогда все, что нам остается, – научиться измерять процесс с учетом этого свойства, то есть придумать некоторый максимально справедливый алгоритм распределения ответственности за нарушение сроков между участниками обработки запроса. Один из таких вариантов метрики в разрезе групп (для произвольной j-той группы) представлен ниже:
| (4) |
где Rij – рейтинг обработки i-того запроса в j-той группе, определяемый формулой
 |
(5) |
а Wij – вес i-того запроса для j-той группы, определяемый формулой
| (6) |
В (5)-(6) tij – время обработки i-того запроса в j-той группе, Ti – максимальное время обработки i-того запроса. n, как и в (3), натуральный параметр алгоритма (обычно равный 1).
Рассмотрим показатель K1,3 подробнее:
- если запрос обработан своевременно, Rij и Wij равны 1, все в порядке;
- если запрос просрочен, причем j-тая группа обрабатывала его дольше, чем полный срок обработки Ti, рейтинг Rij равен 0, вес Wij больше единицы пропорционально времени обработки в группе. То есть группа, потратившая все время, выделенное на обработку запроса, получает снижение значения метрики K1,3 абсолютно аналогично K1,2;
- если запрос просрочен, но j-тая группа обрабатывала его, например, в течение половины срока, вес Wij равен 1, рейтинг Rij равен 0,5. То есть группа получает промежуточный штраф, величина которого тем больше, чем больше времени она удерживала запрос;
- наконец, если какая-то группа обрабатывала просроченный запрос в течение очень короткого времени и, следовательно, вряд ли существенно повлияла на его просрочку, рейтинг Rij будет близок к 1, то есть снижение значения метрики K1,3 для этой группы будет весьма незначительным.
Иными словами, показатель K1,3 работает следующим образом: если запрос просрочен, все участники его обработки получают штраф, величина которого тем больше, чем дольше данная группа удерживала запрос. Каждый мог отработать чуточку быстрее, чтобы запрос был исполнен в срок, каждый и получает по заслугам.
Скорость устранения инцидентов
Ну что ж, с оценкой своевременности обработки запросов мы разобрались. А как измерить, был ли инцидент устранен скорейшим образом, то есть было ли время его решения минимально?
Строго говоря, подтвердить минимальность времени устранения инцидента каким-либо простым расчетом нельзя. Вот опровергнуть – можно. Например, если сегодня некоторый инцидент решался дольше, чем вчера. Поэтому при анализе результативности процесса в отношении инцидентов важно помимо метрик своевременности K1,1-K1,3 наблюдать за динамикой среднего времени решения инцидентов.
Расчет среднего времени решения инцидентов следует выполнять в разрезе значений параметра, который определяет нормативный срок. Например, если срок решения инцидента определяется уровнем влияния, среднее время решения разумно для каждого уровня влияния рассчитывать отдельно.
Кроме того, некоторую дополнительную уверенность руководства в том, что инциденты решаются быстро, могут обеспечить метрики, контролирующие отдельные ключевые практики процесса. В самом деле, если значительная часть инцидентов решается в ходе первичного звонка пользователя, функциональные группы оперативно реагируют на назначенные им инциденты и запросы, специалисты активно используют базу знаний, инциденты и запросы обрабатываются своевременно, а среднее время решения инцидентов с течением времени постепенно снижается, это и есть свидетельства того, что процесс результативен. Верно?
Удовлетворенность пользователей качеством ИТ-поддержки
Верно, но с одним добавлением – необходимо учесть и точку зрения потребителей услуг, понять, приводят ли наши усилия к тому, что их ожидания в части поддержки оправдываются. Ведь, как говорил Питер Друкер, «Качество — это не то, что вы вкладываете в продукт или услугу. Это то, что от них получает заказчик».
Управление инцидентами и запросами в этом смысле очень удобный процесс – ведь в ходе обработки обращений пользователей у нас есть непосредственный контакт с пользователями, и, следовательно, оценить их удовлетворенность несложно. Мы используем два основных способа измерения:
- оценка удовлетворенности пользователя непосредственно перед закрытием его обращения;
- проведение целевых опросов пользователей.
Оценка удовлетворенности непосредственно перед закрытием обработанного обращения, как правило, обеспечивается средствами web-интерфейса системы автоматизации ITSM-процессов или по телефону – пользователя просят оценить, насколько он удовлетворен оказанной ему поддержкой по некоторой балльной шкале. Иногда таких шкал несколько, например оценка скорости поддержки, вежливости специалиста, доступности для пользователя информации по обработке его обращения. Средний балл по этим показателям за период может являться основанием для оценки. Более того, такая информация может помочь выявить несоответствие нормативов на поддержку ожиданиям пользователей, если показатели своевременности решения «на высоте», а многие пользователи оперативностью поддержки не удовлетворены (или наоборот). Еще один плюс – такие оценки всегда персонифицированы (ведь заявитель обращения известен), а значит, вы можете анализировать информацию в различных разрезах: центральный офис и регионы, различные языки, разные способы обращения за поддержкой (телефон, e-mail, web-интерфейс, ...), ИТ-услуги, по которым поступают обращения, и так далее. Наконец, эти показатели можно считать в разрезе отдельных функциональных групп и даже ИТ-специалистов, чтобы индивидуально оценивать их работу (что, впрочем, опять же осложнено функциональной эскалацией – обращение пользователя может быть последовательно обработано несколькими специалистами).
Проведение целевых опросов пользователей позволяет выполнить более комплексную оценку их восприятия и в том числе получить дополнительные пожелания по тому, что именно пользователи хотели бы изменить в первую очередь. Обычно такие опросы проводятся не чаще одного раза в квартал и не реже одного раза в год. Некоторые соображения по проведению опросов представлены в заметке «Процессная математика. Опросы пользователей» на портале RealITSM.
Численную оценку ответов пользователей (полученных как при закрытии их обращений, так и в результате проведения опроса) по произвольной целочисленной шкале удобно представить следующим образом:
| (7) |
где M – средний балл по ответам пользователей, Mmin и Mmax – минимальный и максимальный баллы по шкале оценок (для пятибалльной шкалы Mmin = 1, Mmax = 5).
Итоги по измерению результативности процесса
Таким образом, на практике результативность процесса управления инцидентами и запросами пользователей определяется тремя наборами показателей: своевременность обработки инцидентов и запросов, среднее время устранения инцидентов, показатели удовлетворенности потребителей услуг.
Теперь приступим к измерению ключевых практик процесса, обеспечивающих его результативность.
Измерение ключевых практик процесса
Оперативность реагирования на назначенные инциденты и запросы
Давайте представим, как в реальности происходит обработка инцидента, поступившего от пользователя. Допустим, первая линия приняла и зарегистрировала инцидент, затем направила его в профильную группу. Специалисты профильной группы реагируют не мгновенно – они заняты и обработкой других инцидентов, и другой работой, не связанной с поддержкой пользователей. Поэтому инцидент попадает в очередь и некоторое время ждет, когда же им займутся (это время называется временем реакции). Затем специалист открывает его, принимает в работу, выполняет диагностику и принимает решение о назначении инцидента в другую группу. Инцидент снова попадает в очередь. И так далее.
В результате существенную долю общего времени обработки инциденты просто лежат в очередях (и это суммарное время реакции тем больше, чем больше переназначений). А поскольку мы, согласно назначению процесса, боремся за скорейшее устранение инцидентов, нам очень важно управлять временем реакции и, следовательно, измерять его. Как это сделать?
Время реакции – это характеристика работы отдельных групп. Поэтому и измерять его нужно в разрезе групп. Пример метрики по оперативности реакции для произвольной j-той группы представлен в формуле (8).
| (8) |
где tij – время фактической работы над i-тым инцидентом в j-той группе (за вычетом времени реакции), qij – время реакции на i-тый инцидент в j-ой группе, Nj – общее количество назначений инцидентов в j-тую группу за отчетный период.
Чем ближе значение метрики K1,5 к 0, тем большую долю времени инциденты проводят в очередях, чем ближе к 1, тем быстрее реагируют на поступающие инциденты.
Анализ значений данной метрики можно организовать, например, следующим образом: сформировать таблицу с расчетом по каждой группе двух показателей:
- оперативность реакции на инциденты (K1,5);
- количество инцидентов, назначенных в группу за период, в расчете на одного сотрудника группы.
Далее отсортировать таблицу сначала по оперативности реакции, потом по количеству инцидентов и, двигаясь сверху вниз совместно с руководителями групп, разбираться в текущей ситуации и в том, какие меры можно предпринять для повышения оперативности реакции.
Важный момент: несмотря на то, что метрика K1,5 нормирована и предполагает постановку целевых значений, не следует ставить ее в качестве KPI старшим групп. При использовании её в качестве KPI возможна манипуляция, которая заключается в том, что сотрудники группы каждый поступивший инцидент будут как можно скорее брать в работу, несмотря на отсутствие ресурсов, чтобы приступить к его решению. Это маскирует проблему и увеличивает время решения, поскольку неизвестно, какой специалист освободится раньше – тот, который принял инцидент (не приступив к его решению) или другой, который, освободившись, просто не увидит его.
Кроме того, для повышения оперативности реакции и обработки важно, чтобы при передаче инцидента или запроса в другую группу, собиралась и сохранялась в системе автоматизации информация, как можно более точно характеризующая ситуацию для следующего участника обработки. В общем случае измерить точность и полноту информации, сопровождающую переназначенный инцидент или запрос, не так-то просто – единственное, на что можно опираться, это опрос специалистов. Но в некоторых частных случаях такое измерение может быть и более объективным, и менее трудоемким. Например, можно измерять долю запросов пользователей, переданных с первой линии поддержки, с заполненными опросниками, приложенными скриншотами – с соблюдением установленных правил сбора информации. Однако если вы хотите, чтобы такое измерение давало основание для оценки работы первой линии поддержки, необходимо, чтобы соответствующие правила сбора информации были установлены, а первая линия была снабжена необходимым инструментарием (опросниками, диагностическими скриптами, средствами удаленного подключения к компьютерам пользователей и так далее).
Минимизация переназначений инцидентов и запросов
Как мы видели в предыдущем разделе, переназначение инцидентов и запросов между группами увеличивает общую длительность решения за счет времени реакции. Поэтому вполне естественным является стремление сократить количество переназначений.
Если инцидент поступает на классическую первую линию, самый быстрый способ решения – непосредственно на первой линии, без функциональной эскалации. Поэтому значимой метрикой процесса является показатель FLR (first-line resolution, решение на первой линии поддержки):
| (9) |
где R – количество обращений, решенных на первой линии поддержки, N – общее количество обращений, поступивших на первую линию за отчетный период.
Целевое значение метрике FLR выбирается индивидуально, в зависимости от уровня компетенции первой линии поддержки. Нам встречались значения в диапазоне от 2-3% (первая линия в основном принимает и маршрутизирует обращения) до 95-98% (экспертная первая линия).
Если вам важно, чтобы первая линия выполняла не только регистрацию и маршрутизацию обращений, но и решала их, показатель FLR может быть установлен в качестве KPI для старшего первой линии или включен в контракт с внешним поставщиком, оказывающим вам услуги первой линии поддержки. Но борьба за увеличение FLR не должна приводить к падению доступности первой линии, как точки контакта с пользователями. Поэтому эти метрики обычно балансируют такими показателями доступности первой линии, как доля звонков, принятых без превышения времени ожидания абонента на линии, и доля обращений по web/e-mail, принятых в обработку первой линией в установленный срок. Дополнительно ограничивают и контролируют среднюю продолжительность телефонного разговора оператора с пользователем.
Однако, в последние годы с развитием web-порталов, осуществляющих автоматическую маршрутизацию обращений по профильным группам специалистов, минуя выделенную первую линию поддержки, значимость показателя FLR снижается. Точнее, этот показатель принимает другую форму – доля обращений, обработанных без избыточных переназначений:
| (10) |
где An – количество обращений, обработанных с привлечением n и менее групп, N – общее количество обращений, обработанных за отчетный период. Параметр n часто принимают равным 1 или 2 (реже – 3, если такова специфика маршрутов эскалации в конкретной организации). Причем при n=1 метрика K1,7 превращается в долю обращений, обработанных без переназначений (одной группой). А поскольку первая линия тоже может рассматриваться, как одна из групп, то математически FLR является частным случаем метрики K1,7.
Как и в случае с FLR, использование метрики K1,7 в качестве KPI (особенно KPI старших групп при n=1) требует введения каких-либо балансирующих метрик или других мер, препятствующих неоправданно долгому удержанию инцидентов и запросов в тех или иных группах поддержки. Иначе может возникнуть ситуация, когда менее квалифицированная группа, стремясь повысить свой KPI, будет до последнего пытаться обработать запрос или инцидент своими силами, эскалируя его на следующую линию поддержки слишком поздно – вплотную к окончанию срока обработки, что повышает среднее время решения и вероятность нарушения установленных сроков.
Дополнительной метрикой, характеризующей скорость поддержки при взаимодействии с пользователем по телефону или средствам передачи мгновенных сообщений (Instant messaging), является FCR (first-call resolution, решение в ходе первичного звонка):
| (11) |
где C – количество обращений, решенных в ходе первичного звонка пользователя, N – общее количество обращений, поступивших в заданную группу за отчетный период.
Эта метрика, как правило, применяется к первой линии поддержки, но может использоваться и для оценки других групп, если они участвуют в приеме обращений пользователей.
Повторное использование знаний по поддержке
Повторное использование знаний по поддержке можно измерить следующим образом:
| (12) |
где K – количество инцидентов и запросов, решенных с применением базы знаний, N – общее количество инцидентов и запросов, решенных за отчетный период.
Для того чтобы этот показатель можно было рассчитать, система автоматизации ITSM-процессов должна уметь связывать инцидент или запрос со статьей базы знаний, которая была применена при решении. Однако, на практике многие специалисты применяют известные им решения без ссылок на базу знаний, занижая значение данного показателя. Чтобы этого не происходило, можно найти дополнительные стимулы ссылаться на базу знаний. Например, ссылка на базу знаний может обеспечить подстановку в инцидент готового описания решения. Описывать решения ИТ-специалисты не очень любят, поэтому этой возможностью пользуются весьма охотно. А мы взамен получаем более точные значения показателя K1,9.
Однако обычно показатели K1,9 далеки от 1. Поэтому если вы стимулируете накопление знаний и хотели бы получить соответствующий KPI для старших групп, удобно нормировать K1,9 на целевое значение. Например, при решении обращений статьи базы знаний, созданные некоторой группой, используются в 15% случаев. Вы бы хотели в течение квартала поднять этот показатель до 25% (обозначим это значение как T1,9). Тогда KPI на соответствующий отчетный период для старшего данной группы может быть определен следующим образом:
| (13) | |
Начальное значение этого KPI будет равно 0,15/0,25 = 60%. По его приближению к 100% вы сможете оценить прогресс в решении поставленной вами задачи – формировании статей базы знаний, которые чаще используются на практике, внося свой вклад в сокращение времени обработки инцидентов и запросов.
Решение инцидентов и запросов с первой попытки
Метрика по данной ключевой практике процесса представляет собой долю инцидентов и запросов, решенных с первой попытки (без доработки). Рассчитывать значение этой метрики также полезно в разрезе групп. И переназначения инцидентов из одной группы в другую здесь, к счастью, не помеха, поскольку система автоматизации в состоянии установить отметку, в какую именно группу возвращен на доработку инцидент или запрос. Определение метрики:
| (14) |
где Sj – количество объектов, возвращенных на доработку в j-тую группу, Nj – общее количество объектов, обработанных за период силами j-той группы.
На возврат инцидентов и запросов в работу уходит значительное время, поскольку пользователи, также как и ИТ-специалисты, обычно реагируют не мгновенно. Поэтому на практике большинство инцидентов и запросов, возвращенных на доработку, оказываются просроченными. В связи с этим метрика K1,10 чаще всего используется не как самостоятельный KPI, а как дополнительный аналитический признак, позволяющий раскрыть одну из причин нарушений сроков обработки, демонстрируемых показателями K1,1-K1,3.
Подводим итоги
Мы рассмотрели структурированный набор показателей, предназначенных для измерения и оценки процесса управления инцидентами и запросами пользователей, а также обсудили некоторые аспекты применения этих показателей на практике. Краткая сводная таблица с информацией по показателям процесса представлена ниже:
| Область оценки | Показатель | Оцениваемая роль |
| Результативность процесса | Своевременность обработки инцидентов и запросов (K1,1-K1,2) | Менеджер процесса |
| Своевременность обработки инцидентов и запросов группами поддержки (K1,3) | Старшие групп поддержки | |
| Среднее время устранения инцидентов | Менеджер процесса Старшие групп поддержки | |
| Показатели удовлетворенности пользователей (K1,4) | Менеджер процесса Старшие групп поддержки | |
| Оперативность реагирования на инциденты и запросы | Оперативность реагирования на инциденты и запросы (K1,5) | Старшие групп поддержки |
| Минимизация переназначений инцидентов и запросов | First line resolution (K1,6) | Старший первой линии |
| Доля обращений, решенных без избыточных переназначений (K1,7) | Менеджер процесса | |
| First call resolution (K1,8) | Старший первой линии Старшие групп поддержки | |
| Повторное использование знаний по поддержке | Доля обращений, решенных с применением базы знаний (K1,9) | Старшие групп поддержки |
| Решение инцидентов и запросов с первой попытки | Доля инцидентов и запросов, решенных с первой попытки (K1,10) | Старшие групп поддержки |
Сноски
- Смотри, например, «Review of recent ITIL® studies for APMG» by Rob England, APM Group Ltd, 2011.
- Ключевые практики процесса управления инцидентами удобно выявлять методом Expanded incident lifecycle, представленным в книге ITIL Service Design (ISBN 0113313055), раздел 4.4.5.3.
- Здесь и далее в рамочке справа от определения метрики приводятся сведения о ее нормировке и целевой динамике: «[0; 1]» означает, что значения метрики находятся в диапазоне от 0 до 1 включительно (или 0 до 100% - как вам удобнее), «↑» значит, что чем выше значение, тем лучше.
- Здесь и далее максимальное время (длительность) обработки определяется планами работ или или нормативами, в зависимости от того, как реализован процесс.
- См. статью «Управление уровнем ИТ-услуг. Часть 2. Каталог ИТ-услуг и процессы»




